常见问题解答#
你有很多问题。我们有答案。
当我运行 show(...) 时为什么什么都没发生?
Interpret 的可视化设计为在类 Jupyter notebook 环境(如 Jupyter notebook、VS Code、Colab 等)中工作效果最佳。如果你从命令行脚本运行 show(),可能无法直接渲染可视化内容——请检查控制台输出,看是否有可在浏览器中打开的链接。
默认情况下,Interpret 使用 Plotly Dash 在本地 Web 服务器上托管可视化内容。在某些受限环境中,不允许应用程序托管本地 Web 服务器,我们直接将可视化内容嵌入到 notebook 中。如果 Interpret 未自动检测并切换渲染模式,你可以在受限环境中手动使用以下代码嵌入可视化内容:
from interpret.provider import InlineProvider
from interpret import set_visualize_provider
set_visualize_provider(InlineProvider())
InlineProvider 与 Interpret 中默认的渲染逻辑相比,兼容的环境范围更广。但是,警告:调用 show() 时性能可能会变慢,并且 InlineProvider 目前不支持完整的 Interpret 控制面板。
如何生成完整的 Interpret 控制面板,而不是小的单解释下拉菜单?
确保你向 show 传递的是解释的 列表。注意,你也可以传递一个包含单个解释的列表。例如:
from interpret import show
show(ebm_local) # Returns small dropdown
show([ ebm_local ]) # Produces interpret dashboard
如何提取用于可视化解释的基础数据?
Interpret 中的每个解释对象都支持 .data() 方法,该方法返回一个 JSON 兼容的字典,其中包含用于生成可视化的基础数据。大多数解释包含许多可视化内容——例如,explain_local() 调用会为传递给函数的每个单独实例生成可视化内容。data 接受一个参数,该参数用于索引解释对象并返回用于该个体解释的数据(例如:explanation.data(0) 返回用于对象中第一个可视化内容的数据)。要返回用于所有可视化内容的数据,请使用 -1 键 (explanation.data(-1))。
如何将解释图保存到磁盘?
每个解释图都是一个 Plotly 对象,可以通过 UI 中的相机图标保存到磁盘:
或使用 Plotly 静态图像导出 工具。你可以通过以下方式访问单独的 Plotly 图形:
ebm_explanation = ebm.explain_global()
plotly_fig = ebm_explanation.visualize(0)
例如,将全局解释中的每个图保存到磁盘上的“images”目录:
ebm_global = ebm.explain_global()
for index, value in enumerate(ebm.feature_groups_):
plotly_fig = ebm_global.visualize(index)
plotly_fig.write_image(f"images/fig_{index}.png")
每个图底部的“密度”是什么意思?
密度是描述该特征数据分布的直方图(使用传递到 explain_* 方法中的任何数据进行估计)。在可视化解释时,了解特征空间中每个区域有多少数据通常很有用——模型在处理大样本和小样本时性能可能差异很大。
Interpret 是否支持图像和文本数据的可解释性?
暂时不支持,但请关注未来的版本!
如何只安装单个解释器,而不安装其他依赖项?
对于高级用户,可以直接从 interpret-core 基础包安装。例如,如果你想只安装 EBM 而不安装其他解释器,请运行下面的代码块:
pip install interpret-core[required,ebm]
interpret-core 提供的各种安装选项在 interpret-core 的 setup.py 文件中指定。required 标签通常建议用于所有安装。
为什么图表中不显示特征名称?
如果你向解释器传递的是 numpy 数组,请确保设置了 feature_names 属性(可以在初始化时传递,或在调用解释函数之前手动设置)。使用 pandas dataframes 时,这应该会自动工作。
EBM
我是否应该对 EBMs 进行参数调优(如果应该,应该调哪些参数)?
通常,EBMs 的默认参数在大多数问题上都能表现良好。我们建议使用默认参数训练模型,并在参数调优之前查看学习到的函数以捕捉异常行为——通常,这些图有助于指示要调优哪些参数。以下是一些一般性建议:
为了获得最佳模型,我们通常建议将
outer_bags和inner_bags都设置为 25 或更大。这会显著增加算法的训练时间,对于大型数据集可能不可行,但倾向于生成更平滑的图,并略微提高准确性。如果你认为模型可能过拟合(例如:训练误差和测试误差差异很大,或者图表不稳定),请考虑以下选项:
对于较小的数据集,减少
max_bins,以便将更多数据聚集在一起。通过减少
early_stopping_rounds并增加early_stopping_tolerance,使早停更激进。
相反,对于看起来过于保守的欠拟合模型,你可以采取与之前建议相反的做法——增加
max_bins并使早停不那么激进。增加总允许的max_rounds也可能有所帮助。如果包含的许多交互项都很重要(例如学习到较大的值或在整体重要性列表中排名靠前),那么默认包含的 10 个交互项可能不足以处理你的数据集。考虑增加此数量。
对于一般调优,我们建议对
max_bins在 32 到 1024 之间取值进行扫描,对max_leaves在 2 到 5 之间取值进行扫描。这些改进通常是微小的,但在某些数据集上可能会有显著帮助。
EBM 图上的误差条是什么意思,它们是如何计算的?
误差条是对模型在特征空间各个区域不确定性的粗略估计。较大的误差条意味着学习到的函数可能会因训练数据的微小变化而发生显著改变,并表明在该区域对模型的解释应更加谨慎。
误差条的大小通常由两个因素决定——特征空间该区域的训练数据量,以及学习到的模型的固有不确定性。例如,考虑 Adult 收入数据集中学到的“年龄”特征图:
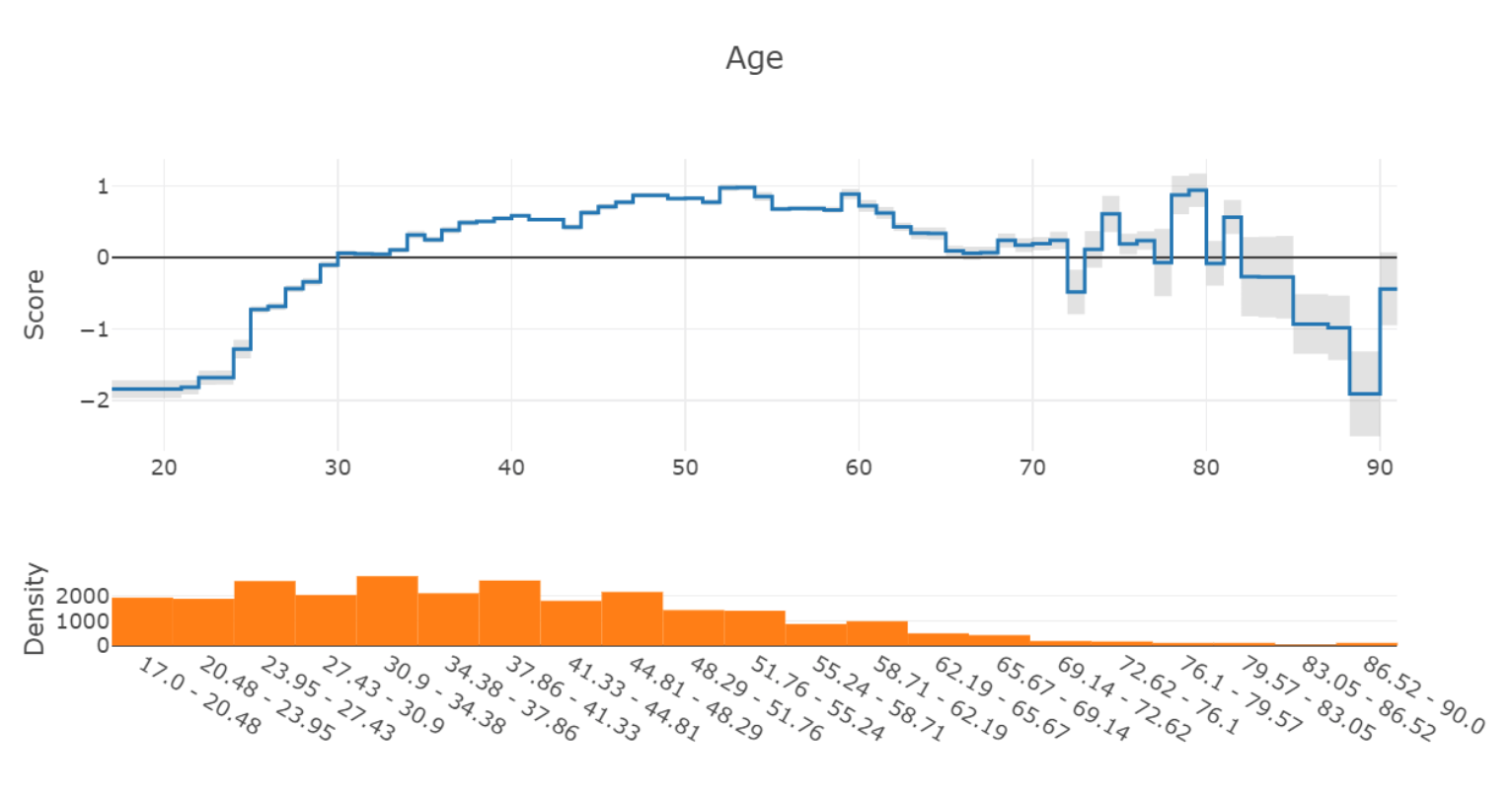
在图的右侧(70岁以上),模型预测变得不稳定,并且误差条变大很多以表明这种不确定性。从底部的密度图可以看出,这很可能是由于该区域的样本数量很少。
误差估计是通过自助聚合(bagging)得出的。默认情况下,EBM 在训练数据集的随机 85% 子样本上训练 8 个不同的 mini-EBM。训练的 mini-EBM 数量由 outer_bags 参数控制,采样数据比例为 1 - validation_size。这些模型的输出被平均以产生最终的 EBM,并且图表中每个区域估计的标准差作为误差条发布。你可以通过任何 EBM 对象上的 standard_deviations_ 属性以编程方式访问误差条的大小。
你们是否提供 EBM 项的显著性 P 值?
暂时还没有,尽管这是一个正在积极研究的领域。如果你有兴趣讨论这个问题或帮助我们解决,请联系我们!
EBMs 在分类和回归中的区别是什么?
这些区别很大程度上类似于线性回归与逻辑回归之间的区别。与逻辑回归类似,EBMs 需要通过使用逻辑连接函数来适应分类设置。
使用此连接函数是因为概率不是加性的——两个特征不能各自贡献 +0.6 的概率给一个预测,因为结果的最终概率 1.2 是未定义的。逻辑连接函数允许模型在 logit 空间中进行训练——其中每个特征的贡献可以是加性的——并在预测时转换回一个有界的概率。因此,在解释 ExplainableBoostingClassifier 的图时,重要的是要记住 y 轴的值是以 logits 为单位的。形状的解释通常是相同的——正值将预测推向该类别的正标签。然而,由于这些图处于对数空间中,+1 或 +2 的差异是相当显著的。
在回归设置中,解释更简单:y 轴的值直接是目标变量的单位。例如,如果你正在训练房价模型,每个图的 y 轴将准确地表示该特征对模型最终价格贡献了多少美元——无需额外的转换!
如何编辑 EBM 模型以移除不需要的学习效应?
最终的 EBM 模型作为 numpy 数组存储在 terms_scores_ 属性中。索引此数组会返回 EBM 中特定项学习到的函数——例如,ebm.terms_scores_[0] 将返回第一个项的数组。直接编辑此数组会更改模型在该图相应区域所做的所有预测。不久将推出一个具有更精细控制的更友好的 API!
我们可以对单个 EBM 项强制执行单调性吗?
可以通过两种方法对 EBM 中的单个项强制执行单调性:
通过在
ExplainableBoostingClassifier或ExplainableBoostingRegressor构造函数中设置monotone_constraints参数。此参数是一个整数列表,其中每个整数对应于相应特征的单调性约束。值为 -1 强制递减单调性,0 强制无单调性,1 强制递增单调性。例如,monotone_constraints=[1, -1, 0]将对第一个特征强制递增单调性,对第二个特征强制递减单调性,对第三个特征强制无单调性。通过对图进行后处理。我们通常建议对每个图的输出使用等渗回归来强制实现正向或负向单调性。这可以通过调用 EBM 对象的
monotonize方法来完成。后处理是推荐的方法,因为它可以防止模型通过在其他高度相关的特征中学习非单调效应来弥补单调性约束。
如何序列化 EBMs 并在生产环境中使用它们?
为了获得完整的功能,我们建议使用 pickle 来序列化和反序列化 EBM 对象。解释可以通过 data 方法序列化为 JSON。
感谢 Github 用户 @MainRo,现在有一个 ebm2onnx 包可用,它可以通过 ONNX 兼容的运行时对 EBM 对象进行高速推理。请在此查看该包:SoftAtHome/ebm2onnx 并通过 PyPi 使用 pip install ebm2onnx 进行安装。
支持
我需要帮助,如何联系?
对于大多数问题,我们建议在 GitHub 上提出 issue。在 GitHub 上解决问题意味着像你一样的其他用户可以从相同的解决方案中受益。对于其他任何事情(或需要保密的问题),请随时发送电子邮件至 interpret@microsoft.com 联系我们。
我有一个好主意,如何贡献?
如果你有想要提交的代码,请务必阅读贡献指南,然后向我们发送 pull request。
如果你想要提出新功能或讨论任何想法,只需在 GitHub 上提出一个 issue。